The plan he walked in with
01A repeat founder - one venture already built, launched, and sold - came in with the brief for Supe, his next build. The target user is the National Sales Manager inside an Indian FMCG brand: the person answering am I on track this month, who is failing, why, and what do I do about it across fifty to five hundred salesmen, ten thousand to a hundred thousand retailers, and a catalogue of fifty to two hundred SKUs. General Trade is eighty-five percent of FMCG sales in India and it runs, today, on paper, WhatsApp, and Excel. Supe is the product that replaces the morning.
He'd already priced the build two ways. The first was vibe-coding. He tried, and he watched it fall apart the moment the AI layer had to do anything beyond wrapping a form - the product he was building leans on the AI being load-bearing, and generative platforms do not compose that shape. The second was hiring our dev team and embedding them in-house for two months. That was the plan he walked in with. We told him the actual build was three days.
Where the AI layer breaks vibe-coding
02Supe is not a dashboard with a chat widget bolted on. The product is organised around a cognitive loop - Briefing, Explore, Ask, Act - and the Ask screen is where the NSM sits for the real work. He types kaunse salesman sabse zyada gir rahe hain, or take Tea Premium to 1Cr in Delhi, or what if I add three salesmen to Karnataka, and he expects numbers back that he will trust on sight.
Trust is the hard part. An LLM that computes the numbers is an LLM that hallucinates the numbers, and an NSM will catch a wrong percentage the first time he opens the screen. So the AI can't do arithmetic. But it also has to do enough - classify the question across eleven possible intents, fuzzy-match the SKU behind atta, decode TN as Tamil Nadu, parse 1Cr as ten million, hold thread context across follow-ups, and narrate the result in a voice the operator will read. Splitting that work - what the LLM does, what the database does, what the deterministic handler does - is the coordination problem generative platforms don't ship.
The four screens, in the order an NSM thinks
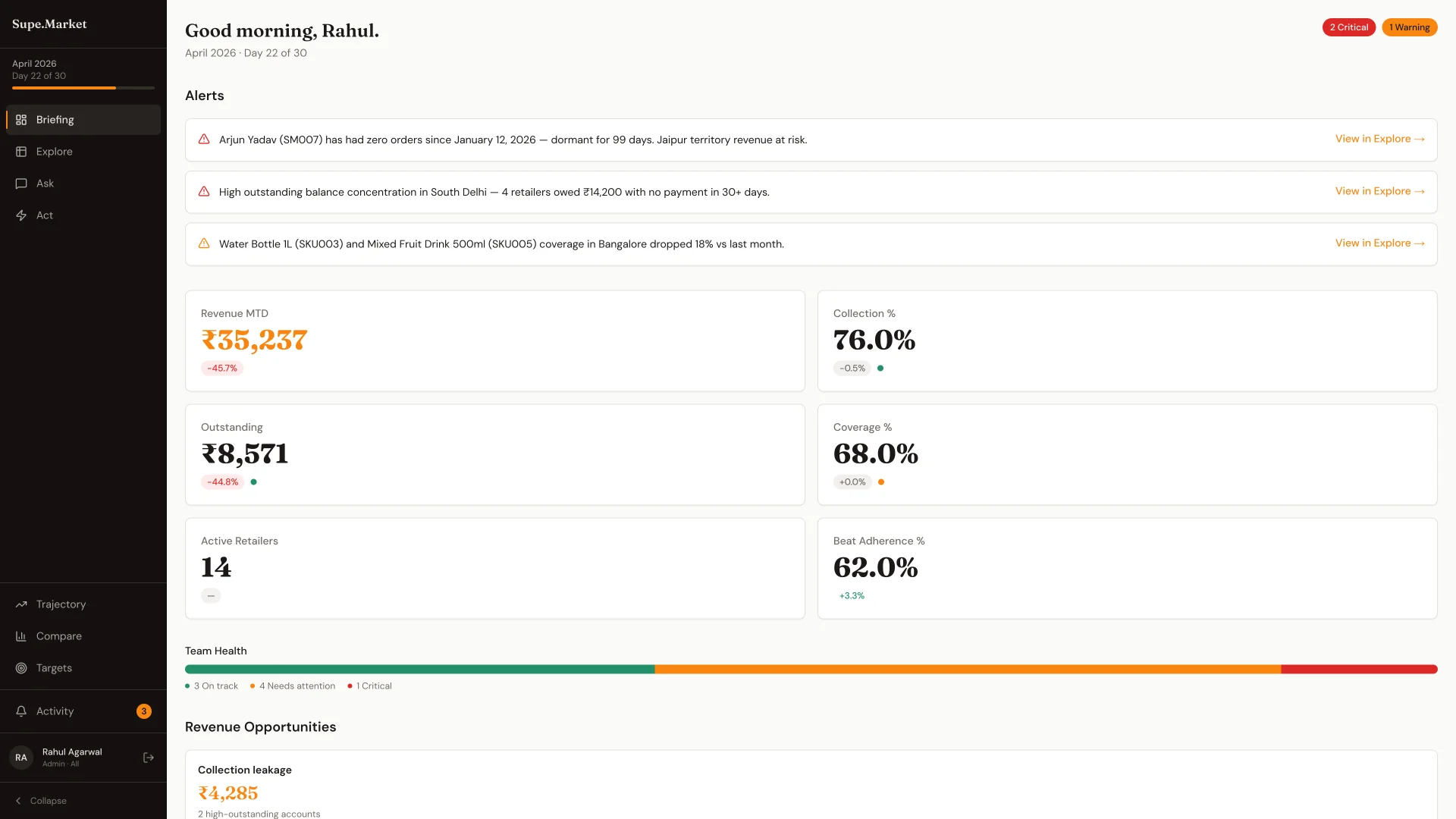
03The product is organised by cognitive step, not by tool type. Briefing opens the day - top alerts ranked by a severity score and naming specific salesmen (Mohammed Khan coverage 65.5% - below 80% threshold for 4 consecutive months), six pulse KPIs, a team health bar in green, amber, red, and revenue opportunities with rupee impact. Explore is the drill-down - salesman, retailer, SKU, distributor, or beat - with a global lens bar for territory, time range, and quantifier, and MoM delta chips inline on every revenue column. Ask is where the cross-referencing happens. Act closes the loop: a signal surfaces on live data, a scheme is pre-filled from a template, WhatsApp messages go out, and the delivery funnel tracks sent → delivered → read → responded.
The three-tier trick behind Ask
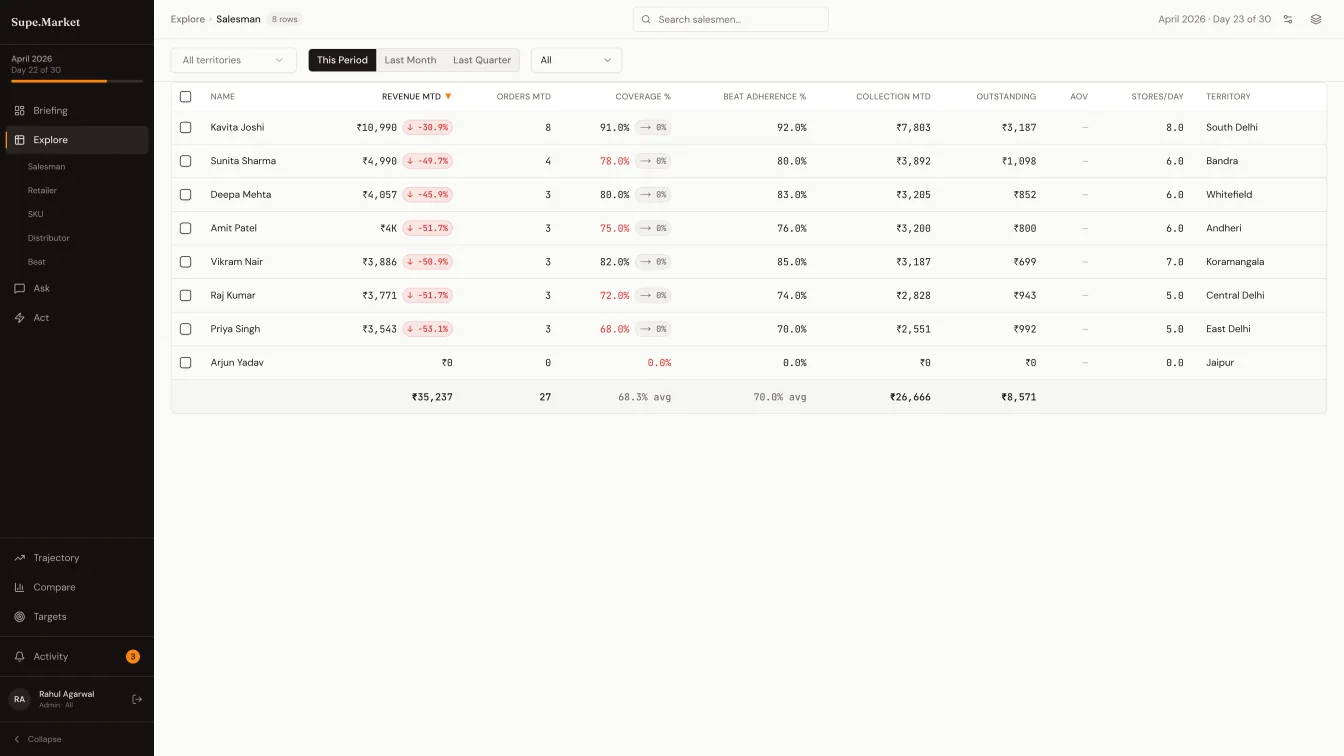
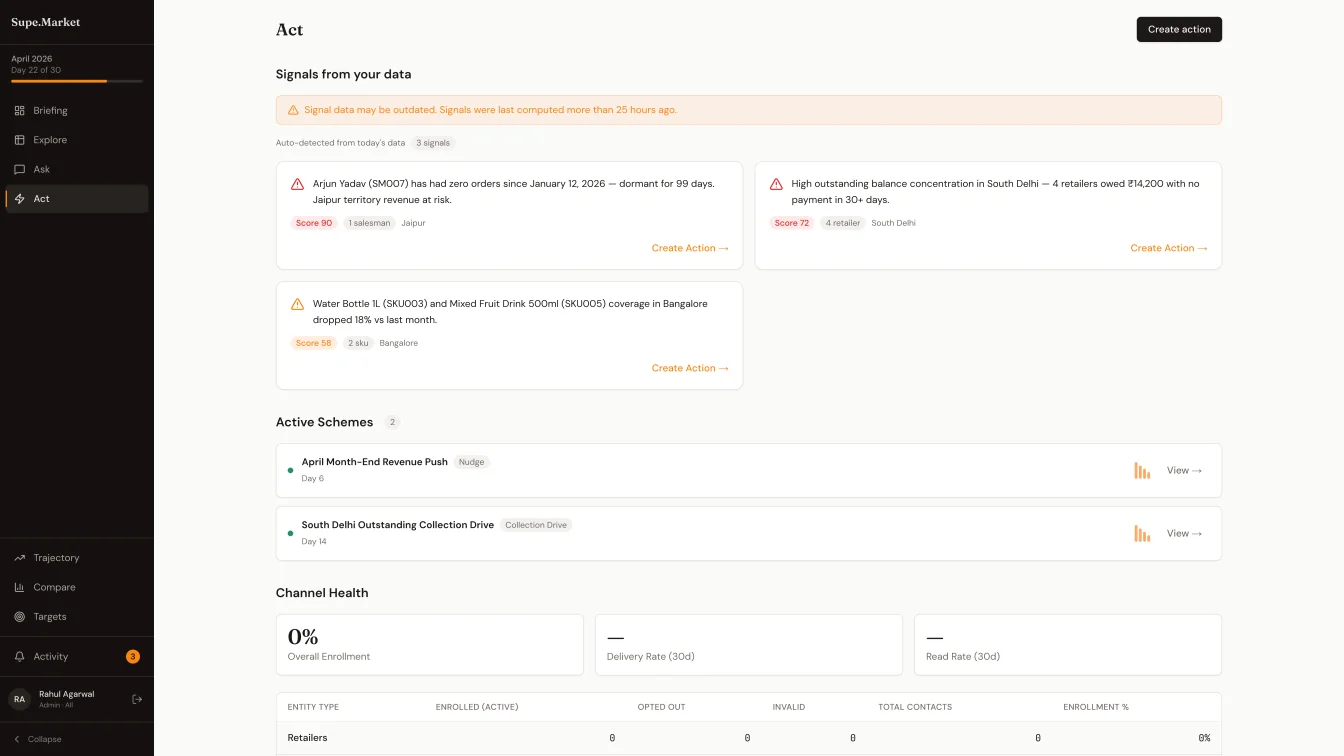
04Every question routes through three tiers, in order. Tier one is regex plus deterministic dispatch - sixty to seventy percent of FMCG questions are predictable (top five salesmen, collection percent this month, dormant retailers last thirty days), and they hit a handler in under ten milliseconds at zero cost. Tier two sends the question to the LLM as a classifier only - classify the intent across eleven shapes, extract the named entities, hand the work off to the same deterministic handlers tier one uses. Tier three is full LLM generation, reserved for the five to ten percent of edge cases that don't map to a template. Even in tier three, the LLM narrates pre-computed numbers. It never generates them.
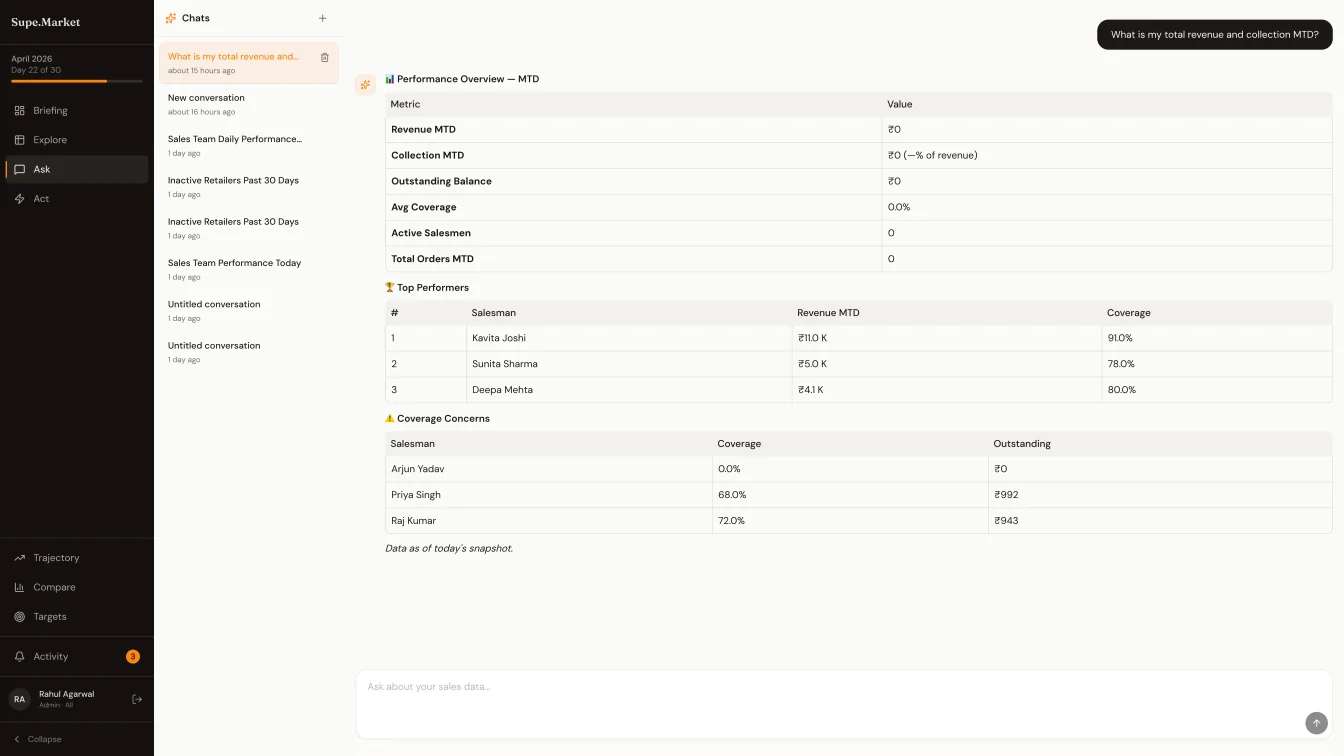
The rule underneath is a single sentence: the LLM never computes arithmetic. Tier two classifies and extracts. Tier three narrates. All numbers run through deterministic code that queries the daily snapshots. When the LLM API is down, tier one still answers sixty percent of the questions. That rule - and the coordination around it - is the thing vibe-coding does not build.
Hindi and Hinglish are handled natively inside tier one across twenty-five patterns - kyu, wajah, kaunse, kitna, agar, paisa kahan - so the NSM is not paying an LLM round trip to answer why is Tamil Nadu underperforming in the language he actually asks the question in.
From insight to action
05After a two-turn conversation - why is Tamil Nadu underperforming?, what would a reactivation scheme cost there? - the Ask engine matches the thread against twenty-eight scheme templates organised across volume, distribution, retailer behaviour, salesman performance, distributor channel, SKU push, seasonal, and competitive categories. A purple card surfaces inline: Based on three turns analysing dormant retailers: Dormant Retailer Reactivation · ₹100/head · 10-30x ROI · Set up in Act. One click lifts the template into the Act wizard, pre-filled. The three-step wizard picks the action type, builds the audience (a behavioural cohort builder with AND-within-groups, OR-between-groups, live preview count), and dispatches the WhatsApp template through the Meta Cloud API.
Scheme outcomes are recorded against a configurable control holdout, so lift is measured against a real counterfactual, not asserted.
Underneath the conversation
06Five entities carry the product - salesman, retailer, SKU, distributor, beat - in a schema that is multi-tenant at the row level. Every lc_* table carries org_id, every repository query enforces it, and any query without the clause is a code-review block. The territory hierarchy is self-referencing and per-org - a national brand picks Country → Zone → State → City, a regional brand picks State → District → Town, and the level names are strings rather than an enum. Targets cascade along the reports_to graph so a Regional Sales Manager's number aggregates the Area Sales Executives underneath him.
Onboarding lifts an Excel export straight out of a distributor's DMS - the data the FMCG world actually has. The importer auto-detects the date format, fuzzy-matches column headers, and auto-creates the salesmen, retailers, SKUs, distributors, and beats that appear in the orders. Fourteen WhatsApp templates are pre-registered with Meta; opt-in status, delivery state, and responses are tracked per message, per recipient.
What he's walking into funding rooms with
07He isn't hiring the dev team. He's in conversations with funds, and the artifact under the conversation is a platform that already runs - the Ask engine, the scheme loop, the multi-tenant schema, the WhatsApp delivery funnel, the NSM's full morning in one screen.
The team was responsive to every change I requested and delivered high-quality work on time. I feel confident using Creatr for my business needs. This is exactly what I wanted.
The part vibe-coding doesn't ship
08An AI that classifies and narrates but never computes, running on top of a five-entity schema, a per-org territory tree, a twenty-eight template scheme library, and a WhatsApp delivery funnel - shipped as one product that stays consistent with itself - is the specific build generative platforms cannot coordinate. The AI is load-bearing here, not decorative. That's why three days replaced two months.

Co-founder and CTO of Creatr, building DeepBuild: the system that ships production web apps in 24 hours. Prince's open-source WhatsApp userbot, BotsApp, earned 5.5k GitHub stars and 1.3k forks during his college years. He later ran a solo freelance engineering practice to $100K in revenue before co-founding Creatr.